Kubernetes cluster metrics 101

Kubernetes clusters facilitate the management of containerized applications. Imagine coordinating a seamless flow of workloads across servers, ensuring they operate in harmony, regardless of scale. This is exactly what Kubernetes clusters can do for the smooth deployment of your applications. Read on to learn more about Kubernetes clusters, including how to manage them using our list of critical metrics.
What's a Kubernetes cluster, and why is it important to manage?
A Kubernetes cluster is made up of two primary components: a control plane, which acts as the conductor, and a set of worker nodes, which perform the tasks. This orchestration enables seamless scaling, fault tolerance, and automated deployment, empowering teams to focus on building rather than managing infrastructure.
Kubernetes cluster management in 2025 presents its own set of challenges. These arise due to a lack of resource visibility and the rapid increase in employing Kubernetes for application deployments.
Without actionable insights from metrics, problems such as pod failures, resource depletion, or uneven workload distribution can rapidly worsen, affecting application performance. The crucial aspect is maintaining clear insight into the performance and health of your cluster.
Metrics, including CPU and memory usage, status of pods and nodes, will help identify resource bottlenecks and help better resource allocation and maintain seamless operations.
Why Kubernetes metrics matter
Imagine driving a car without a speedometer or fuel gauge. Metrics in Kubernetes are like those dashboard dials. They would indicate the fuel consumption, speed, and security-related alerts. Similarly, Kubernetes metrics give you crucial insights into your cluster's health, availability, and performance. These metrics help you:
- Keep track of CPU, memory, and storage usage.
- Maintain availability at all times.
- Identify bottlenecks early on.
- Scale applications as needed.
- Resolve issues promptly.
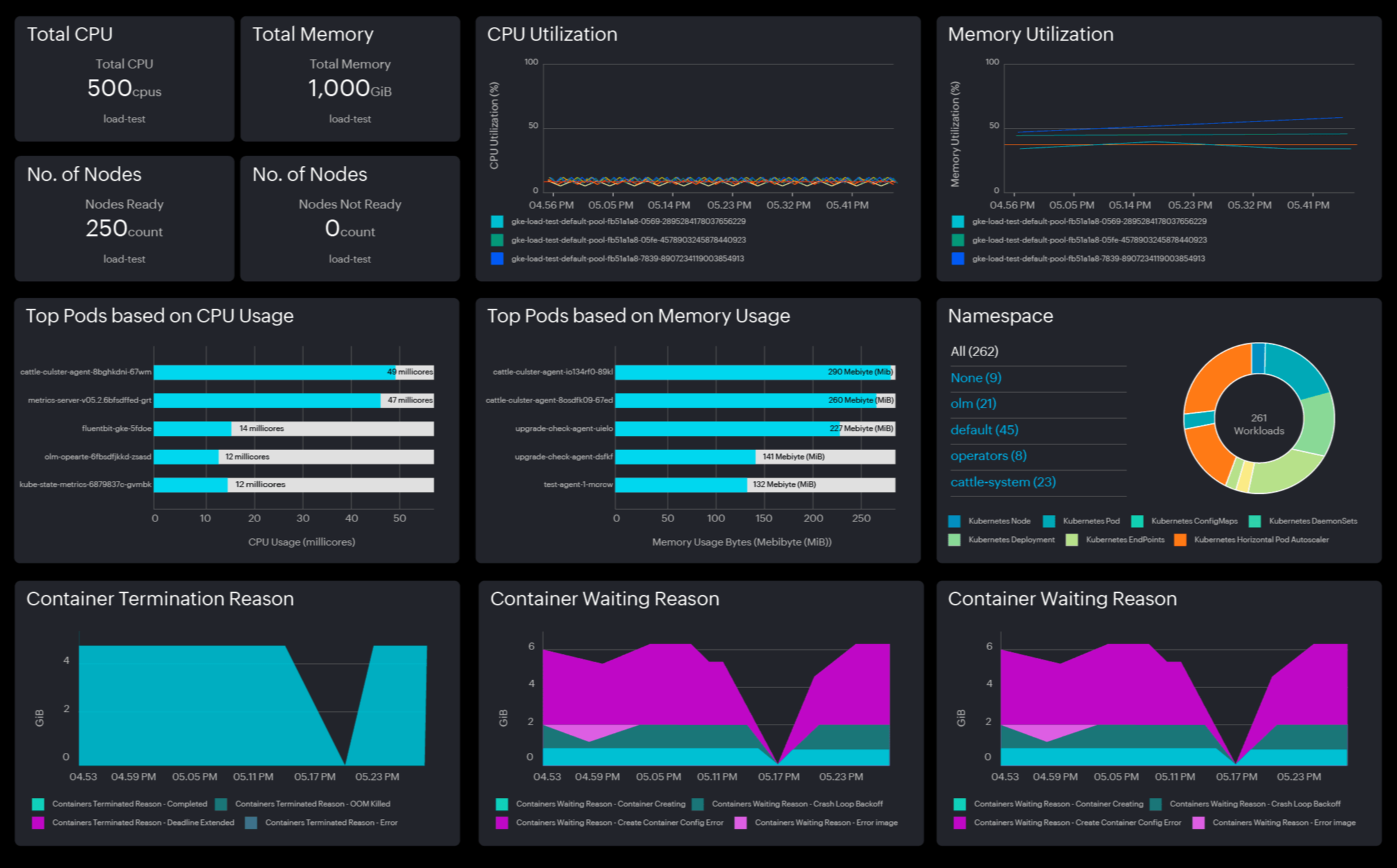
Different levels of Kubernetes metrics
Kubernetes provides a treasure trove of metrics that reveal what's happening in your cluster:
1. Cluster metrics
Cluster metrics offer a consolidated perspective of resource utilization and overall well-being across the cluster, guaranteeing equitable resource distribution and optimal availability.
- Resource allocation:
- Allocatable CPU vs. used CPU and allocatable memory vs. used memory in the cluster.
- Resource fragmentation, showing wasted or unused capacity.
- Disk usage of the cluster to ensure optimal storage.
- Control plane metrics:
- API server request rate, latency, and errors.
- Scheduler metrics, which denote the average time taken by the scheduler to place workloads.
- Read/write request latency of etcd.
- Queue depth and work duration of Controller Manager.
- Cluster events:
- Node failures, pod scheduling issues, or cluster-wide alerts.
- Persistent volume:
- Tracks storage allocation and utilization.
2. Namespace metrics
Namespace metrics offer a detailed perspective on resource utilization and performance in particular namespaces of a Kubernetes cluster. This level of detail aids in monitoring and controlling resources efficiently, guaranteeing equitable allocation and averting resource conflicts among various projects or teams.
- CPU and memory usage: Tracks the total CPU and memory consumption within each namespace to identify resource-heavy workloads.
- Resource quotas: Monitors adherence to defined resource quotas, preventing any namespace from overconsuming shared resources.
- Limit ranges: Observes if pods in a namespace are respecting the set minimum and maximum resource limits.
3. Node metrics
Node metrics focus on the physical or virtual machines that host your Kubernetes workloads. These metrics are critical for understanding node health and performance.
- CPU usage: Tracks the CPU utilization of nodes to detect resource bottlenecks or underutilization.
Metrics include: - Total CPU usage
- CPU throttling to identify restricted performance due to resource limits.
- Memory usage: Highlights how memory resources are utilized, helping you identify nodes that are overloaded or with excessive capacity.
Metrics include: - Allocated vs. used memory
- Disk I/O: Measures the disk read/write operations, indicating potential bottlenecks in data handling.
- Network performance: Tracks data sent/received, helping you identify nodes with communication issues.
- Node condition metrics: Helps detect node-level problems such as disk pressure, memory pressure, or readiness issues.
4. Pod metrics
Pod metrics reflect the performance of individual workloads running within the cluster. These metrics help identify application-level issues:
- Pod status: Metrics such as running, pending, or failed pod counts provide a quick view of workload health.
- Pod restarts: Frequent restarts often indicate underlying issues like insufficient resources or application bugs.
- CPU and memory utilization: Measures actual resource consumption compared to what was requested and limited for the pod.
- Requested resources: Resources a pod expects to consume.
- Limits: Maximum resources allocated to a pod.
- Container metrics:
- Container-specific resource usage for in-depth troubleshooting.
- OOM (Out of Memory) kill metrics to identify resource-starved pods.
- CrashLoopBackOff pinpoints if the container is struggling to start and indicates there is some reason for the failure.
5. Workload metrics
Workload metrics assess the performance of various workload types, such as Deployments, StatefulSets, and DaemonSets.
- Resource usage per workload:
- Tracks CPU and memory consumption at the workload level.
- Identifies resource-hungry applications for scaling or optimization.
- Network traffic and usage:
- Monitors the network traffic and the usage of all the workload components and pinpoints discrepancies to ensure smooth operation.
- Replicas: Ensures that the desired number of replicas for workloads is maintained for high availability.
6. Kubernetes Events
Events are critical for diagnosing and troubleshooting cluster-level issues.
- Pod scheduling failures: Tracks events when pods cannot be scheduled due to resource or configuration limitations.
- Node warnings: Highlights issues like disk pressure, memory pressure, or readiness failures.
- Container life cycle events: Tracks events such as container restarts or crashes for debugging.
- Scaling events: Monitors when workloads are scaled up or down to ensure resource allocation matches application demands.
By combining these detailed metrics with consistent analysis, you can efficiently oversee Kubernetes clusters, address problems, and uphold peak performance for your workloads.
Collecting cluster metrics: How to utilize them for effective K8s monitoring
You don't need to be a Kubernetes expert to keep your cluster running optimally. Just follow these basic steps:
1. Setup
When you sign up for a Kubernetes monitoring tool like Site24x7, you will deploy the Kubernetes monitoring agent in your Kubernetes cluster with a simple YAML file.
The agent discovers your cluster's resources automatically and starts collecting metrics right away.
2. View real-time dashboards
You will be able to view all your critical metrics—CPU, memory, pod health, and more—in one intuitive dashboard. Instantly get to know where issues are brewing, whether it's a single pod or an entire node.
3. Set smart alerts
Avoid surprises by setting thresholds for the above-discussed key metrics. Get notified via email, SMS, or tools like Slack when things go off track.
4. Get actionable insights
Use detailed reports and visualizations to plan better resource allocation. Track trends and predict future needs with historical data.
Final thoughts
Kubernetes metrics aren't just numbers—they're the story of your cluster's health and performance. With Site24x7 Kubernetes monitoring, you have everything you need to collect, visualize, and act on these metrics. From real-time dashboards to proactive alerts, monitoring your Kubernetes environment will keep your cluster running smoothly and efficiently.
Comments (0)